Flavio Biondo: Italia Illustrata, LIBER II, Regio tertia. LATINA
Übersetzung | Translation: Jeffrey A. White
Lizenz | License: Copyrighted content. THE I TATTI RENAISSANCE LIBRARY, HARVARD UNIVERSITY PRESS
Textanalyse: Vorbemerkung (Text Analysis: Introductory Remarks - only in German)
Am Beginn des Projekts stand die Bearbeitung des Latium-Buchs der "Italia Illustrata". Nach White dürfte "der" Text der Italia Illustrata ca. 1460 abgeschlossen worden sein. Biondo starb 1463; die römische editio princeps erschien im Dezember 1474. Von den drei Textausgaben der "Italia Illustrata" (der auf Handschriften beruhenden lateinischen "Nationalausgabe" von Pontari, der auf der editio princeps beruhenden zweisprachigen von White und der auf dem Basler Druck von 1559 beruhenden zweisprachigen von Castner) war für das Projekt die von White ausgewählt worden. Zunächst wurde der Text der - relativ freien - englischen Übersetzung bearbeitet, die jedoch wegen diverser Mängel und der zu großen Distanz zum lateinischen Text für die Forschung nur bedingt geeignet ist.
Die Texte wurden eingescannt und korrigiert. Die Bearbeitung der OCR-Scans des Textes in der Fassung von White erfolgte nach folgenden Richtlinien:
- Satzzeichen bleiben wie in der Edition gegeben; alle Satzzeichen werden durch einen Zwischenraum abgesetzt, am Satzende wird ein Zeilenvorschub eingefügt, so dass jeder Satz auf einer eigenen Zeile steht. Da Doppelpunkte in der Regel Zitate einleiten, gilt auch ein Doppelpunkt als Satzendezeichen.
- Anführungszeichen (Zitate) werden durch ` und ' (linksgeneigter Apostroph und senkrechter Apostroph) ersetzt. Besteht ein Zitat aus mehreren Sätzen, wird jeder Satz separat geklammert.
- Indirekte Rede wird nicht gesondert markiert.
- Alle Fußnoten und weitere Paratexte werden gelöscht.
Der lateinische Text wurde als "Rohtext"-Datei (utf-8) vorbereitet und diente in dieser Form als Eingabe für verschiedene Analysewerkzeuge (Wortlisten, Statistik, Konkordanz, Dependenzparsing, etc.) sowie die Auszeichnung der Latium-Toponyme in Recogito. Für das "Spatial Role Labeling" wurde diese Datei satzweise in insgesamt 626 Dateien zerlegt. Die englische Übersetzung ist damit synchronisiert, kann aber nur zu heuristischen Zwecken dienen; technische Analysen wurden mit dieser Fassung nicht durchgeführt (wohl aber mit inkompatiblen früheren Versionen, die sich jedoch von geringem Nutzen erwiesen, siehe 2.2).
1.1 Lateinischer Text | Latin Text
Formats:
- Rohtext (satzweise) | Plain text (sentence by sentence) Latin
- Rohtext mit Zeilen-/Satznummern | Plain text with line/sentence numbers Latin
- Englische Übersetzung, zeilenweise synchronisiert, mit Zeilennummern | English translation synchronized line by line, with line numbers English
1.2 Textanalyse | Text Analysis: Latin
Formats:
- Alphabetische Wort(formen)liste mit Häufigkeiten (Kleinschreibung) | Alphabetic word (form) list with frequencies [kwc] [txt]
- Nach Endungen sortierte Wort(formen)liste mit Häufigkeiten | Backward (endings sorted) word (form) list with frequencies [kwc] [txt]
- Aufsteigend sortierte Wort(formen)liste (Kleinschreibung) mit Häufigkeiten | Ascending word (form) list with frequencies [kwc] [txt]
- Absteigend sortierte Wort(formen)liste (Kleinschreibung) mit Häufigkeiten | Descending word (form) list with frequencies [kwc] [txt]
- Konkordanz | Concordance (KWIC) [txt]
- Tree-Tagger Wortliste (STTS) mit Lemmata | Word list, Tree-tagged (STTS), with lemmata [txt]
- Tree-Tagger Wortliste (STTS) mit Häufigkeiten, nach Tags sortiert | Word list, Tree-tagged (STTS), with frequencies, sorted by tags [txt]
1.3 Dependenz-Syntaxanalyse | Dependency Parsing (Latin)
... mit dem UDpipe Dependency Parser UD 2.4 und dem Universal Dependencies lateinischen Sprachmodell latin-ittb-ud-2.4-190531.
Format: Alle Ergebnisse [txt] in einer Datei (632 Sätze) im CoNLL-U (Tabellen-) Format.
Die Dependenz-Syntaxbäume können satzweise mit dem CoNLL-U Viewer angezeigt werden; dazu muss die Ergebnisdatei (Postfix ."conllu.txt", selbes Verzeichnis) hochgeladen werden.
Zu anderen lateinischen Sprachmodellen siehe auch diesen Vergleich.
... with the UDpipe Dependency Parser UD 2.4 using the Universal Dependencies Latin Language Model latin-ittb-ud-2.4-190531.
All results in one file (632 sentences) in CoNLL-U (tabular) format.
The dependency trees can be displayed sentence by sentence with the CoNLL-U Viewer by uploading the results file (postfix ."conllu.txt", same directory).
For other Latin language models see also this comparison.
1.4 Spatial Role Labeling
...mit dem brat rapid annotation tool (Annotationswerkzeug). Erlangen website Latin
Der Text wurde zur Annotation aufbereitet, die Daten stehen jedoch noch nicht zur Verfügung.
The text has been prepared for annotation, but the data is not yet available.
1.5 Ein Experiment mit WORDij zur automatischen Erstellung eines semantischen Netzwerks
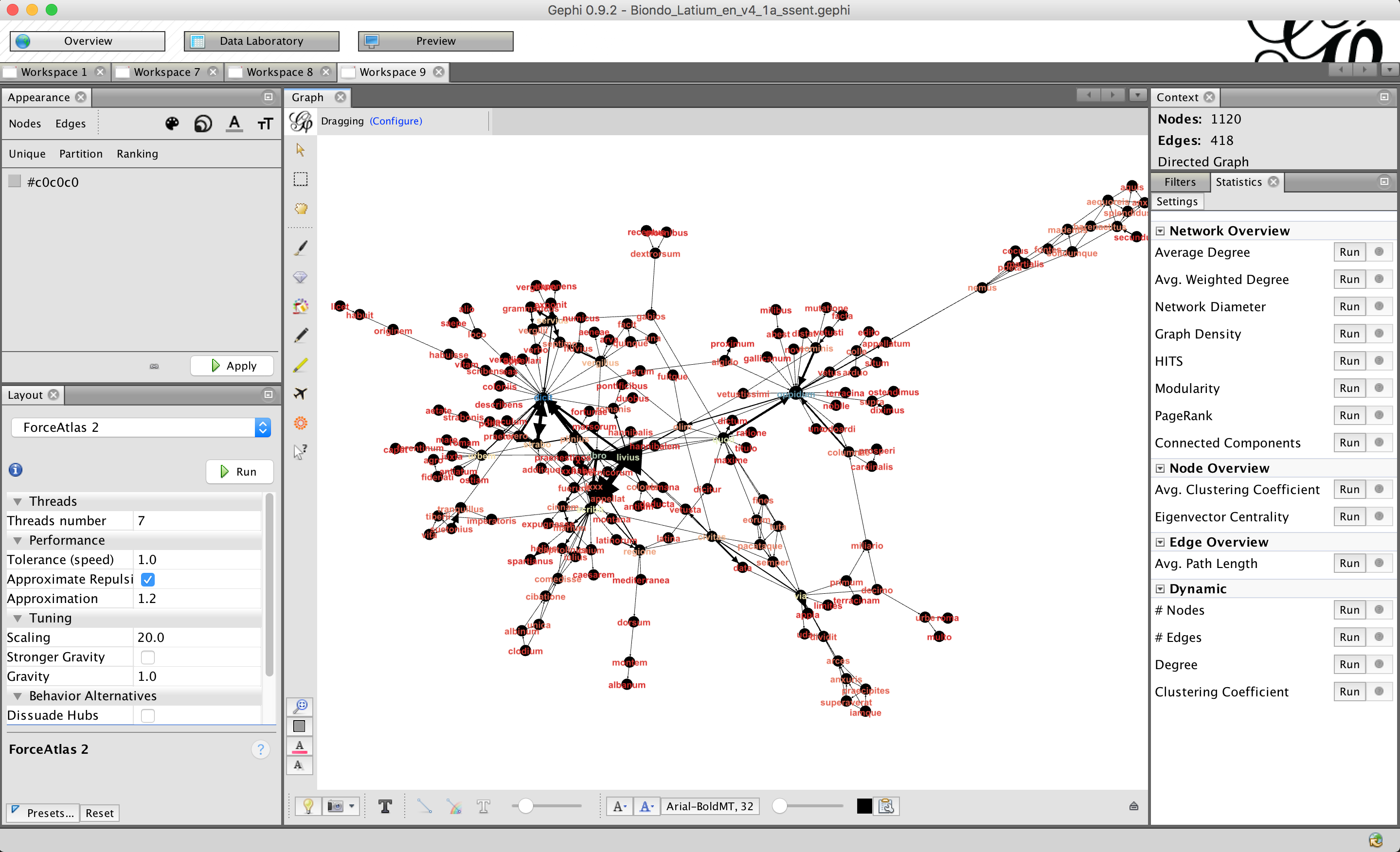
WORDij baut auf der Idee von signifikanten Wort-Kookkurrenzen auf und führt i.W. linguistisch uninformierte Berechnungen über benachbarten Wörtern durch, die in semantisch interessanten Verknüpfungen resultieren. Nach seinem Urheber Danowski ist WORDij ein Textanalyseprogramm, das Wörter als Knoten und Wortpaare als Links für die Netzwerk- und andere statistische Analysen behandelt. Wortpaare werden auf Basis der Wortnähe gebildet, die ihrerseits berechnet wird mittels eines Fensters, das durch den Text gleitet und dabei alle Wortpaare darin zählt.
Ein erster Versuch zur Analyse des (lateinischen) Textes ergab viel versprechende Ergebnisse (Abbildung). Mit dem Werkzeug gephi zur dynamischen Visualisierung von Graphen können semantische Cluster und ihre Zusammenhänge exploriert werden. Weitere Versuche sollten mit verschiedenen Parametrisierungen unternommen werden, wozu jedoch ein Auswertungskonzept für die semantischen Cluster erforderlich wäre.
{kind=link}
Format: Gephi-Datei [bin]
Software
- Danowski, J.A. (2013). WORDij version 3.0: Semantic network analysis software. Chicago: University of Illinois at Chicago. wordij.org
- WORDij/gephi Video Tutorial
- Gephi
Guenther Goerz, FAU Erlangen-Nürnberg, Computer Science, AG Digital Humanities und Bibliotheca Hertziana, Max-Planck-Institut für Kunstgeschichte, Rom.
Last modified: Sat Oct 10 16:55:00 CEST 2020